This article is the first half of a white paper I published with my former colleague and fellow data scientist at Alexander Thamm GmbH, Steffen Bunzel. Read the other half or download the full white paper here.
.
Executive Summary:
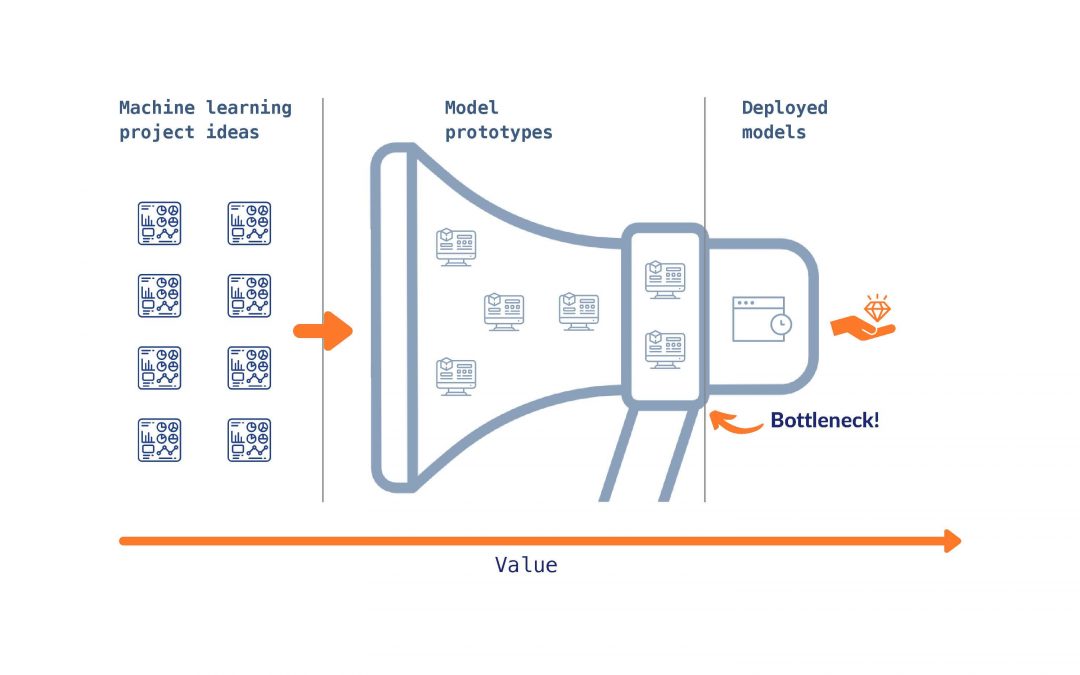
A great leap of faith has been given to the entire data science guild in the past years. Companies across all industries have invested heavily in data science and analytics. Newly created “Data Analytics and AI” departments have been mushrooming in enterprises of all sizes. Yet, many data science teams and projects failed to live up to the expectations that the excitement around data science and AI had sparked. While numerous prototypes and pilots were created, the time for mere experimentation is over. However, many projects are stuck at what we call the “data science bottleneck”: The deployment phase where successful data science pilots are to be put into productive operation.
The reasons for this are:
- Data accessibility and quality may be enough for a prototype, but is not up to par with the requirements of productive use.
- Data privacy and security concerns prohibit scaling.
- The scarcity of data science talent is only matched by the lack of data engineers with experience in building and operating stable data products.
- In many companies, there is a large organizational gap between business, data science and the IT department.
- The technology landscape is quickly evolving and enterprise IT is playing catch up.
.
1. Why do we care about deploying data products?
In the past few years we have witnessed how the hype around data science has dispersed a certain buzzword dust. Data science was regarded by many as a “magic sauce” to increase productivity, save costs, understand customers better and ultimately raise profits. This hype entailed a tremendous leap of faith by decision makers. Companies hired entire data science teams to establish “Big Data Analytics” or “Digital Transformation and AI” departments. These departments mushroomed across industries – in large corporations and SMEs alike. Their mandate: Execute the organization’s digital transformation and usher it into the digital age. Develop new digital business models. Cut costs. Improve customer satisfaction. And help increase profits through the magic of data and AI.
While some companies are still looking for qualified data scientists, for others the dust is starting to settle. Many of their use cases are approachingl the “Data Science Bottleneck” and are waking up to a hangover: Their data scientists have identified some (often shiny) use cases and implemented them in proof of concepts, prototypes or pilots (one quote from the trench was “our company has more pilots than any airline”). However, very few or even none of these use cases was deployed and went into production (see for example here). Data scientists may have created sophisticated models, made use of deep learning and written complex scripts. Yet, they failed to live up to the ultimate goal of data science: To create value from data. Even the best models are to no avail if they are not deployed.
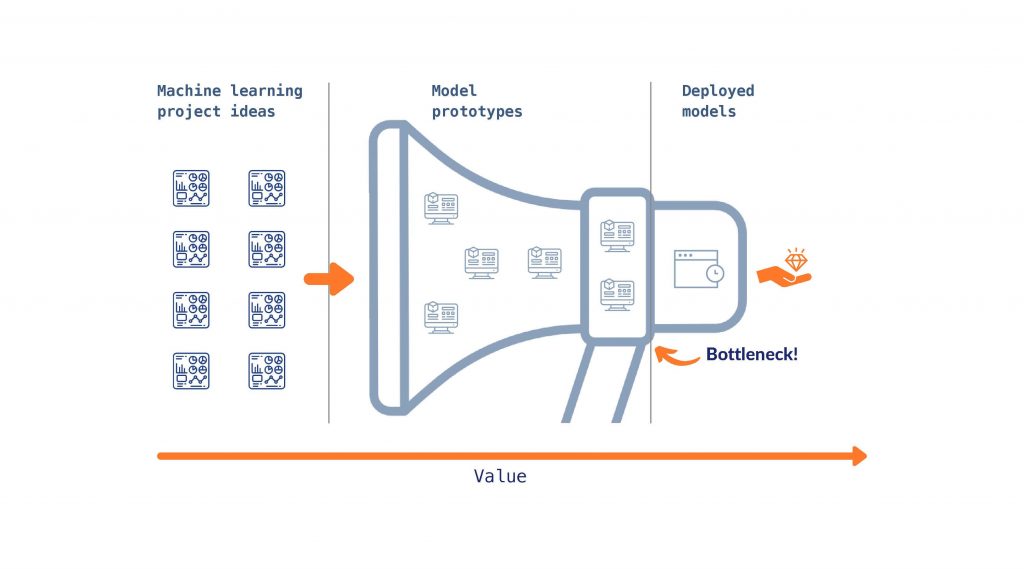
Figure 1: The Data Science Bottleneck
The data science discipline and with it practitioners across industries are therefore entering a crucial phase: They will have to move beyond the hype and live up to the leap of faith that was given to them by the executives. For that, they will have to go the last mile of deploying the models they have come up with in the past.
The Alexander Thamm GmbH, for which I previously worked, has implemented over 500 data science use cases. Implementing some of them I have seen both, use cases that fell prey to the bottleneck and remained prototypes/ PoC (or even failed at that) and use cases that succeeded and are now generating added value as deployed data products in their companies. Drawing upon this experience, these are some common challenges of deploying data science projects.
.
2. What does deploying a data science project mean?
Before diving into the challenges and best practices, let us briefly define what we mean by “deploying a data product”. In traditional software engineering and development, deployment means to “make a system available to its users”. We will use a similar definition for deploying a data science project. Adapting this definition for data science projects raises the question what “system” refers to in this context. The answer is not trivial given that data science spans many disciplines, application areas and use cases. We define the “system to be made available to users” as the output of a successful development and prototyping phase. We call this part of the data science lifecycle “Data Lab”. The output of the Data Lab phase can take various forms. A list of examples could include, but is definitely not limited to:
- A machine learning or statistical model commonly made available as a Python or R implementation of an algorithm or created using high level tools such as MLAzure, AWS Machine Learning, SAS, SPSS or KNIME
- The results of a statistical analysis (e.g. a root cause analysis for quality defects) in the form of a report
- Automatic computation and visualization of a variety of key performance indicators in a dashboard created using a business intellignce tool like Tableau, Qlik or PowerBI
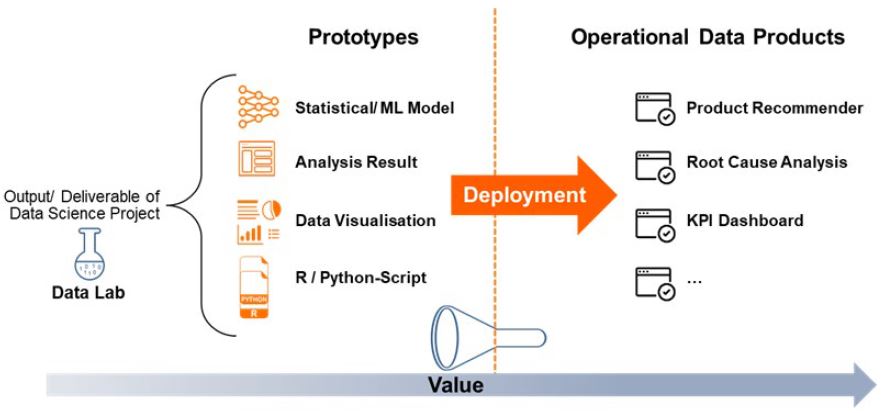
Figure 2: From Prototype to Operational Data Product
We define the deployment of a data science prototype as making its output available to users by integrating it into the respective business process.
Data science project deployment can therefore take various forms. Not only because the outputs vary, but also because business process integration is highly use case specific. To categorize these we employ two criteria: 1) How is the output processed? 2) How frequent is the data ingestion and data access? Figure 3 illustrates these dimensions with examples.
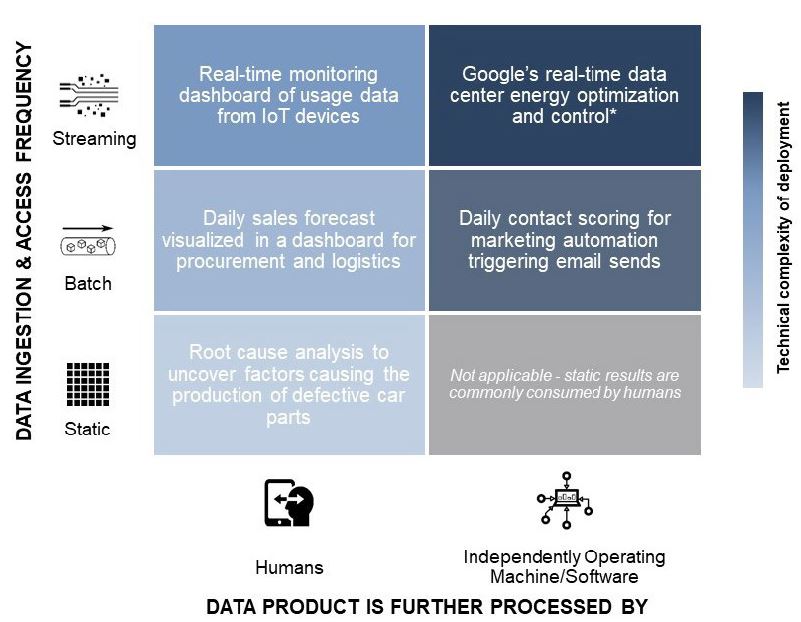
Figure 3: Forms of Technical Deployment | * For more information on Google’s data center cooling use case, see here.
.
Based on this framework we can distinguish three levels of complexity for the technical deployment of data science projects:
| Low complexity | Medium complexity | High complexity | |
|---|---|---|---|
| Data product is processed and used by | Humans | Humans | Machine / Software / Application |
| Frequency of data ingestion and access to output | Once | Regular basis (batch processing every day / week / month) or constantly (streaming) | Regular basis (batch processing every day / week / month) or constantly (streaming) |
| Examples | Root cause analyses are typically performed on a static data basis. For example, the quality and production data for the past year could be analyzed using various statistical methods to uncover influencing factors from production on quality defects in the field. The results of such an analysis would then be shared with production process and quality engineers via static notebooks, reports or presentations. Based on these, the process experts could draw conclusions and derive optimization possibilities. While the data acquisition and preparation as well as the statistical modeling can be very complex for use cases like these, a technical deployment step as such is usually not necessary. |
This cluster of use cases is characterized by a dynamic data basis for algorithms and visualizations whose results are directly consumed by humans. Where they differ is the data ingestion and access frequency: A machine-learning-based daily sales forecast for each category in a retailer’s product assortment can be recalculated in batch each night and made available to the procuremen or logictics department using a dashboard. Based on this information, the professionals within these business functions optimize their decision making without having the predictions embedded in a prescriptive system ordering raw products and planning inventory levels autonomously. For some use cases, however, daily is not frequent enough. For example, for IoT devices in the consumer space, but especially within a production facility or a corporate supply chain, real-time data flow might be necessary to allow for effective monitoring. Naturally, this requirement creates additional complexity in building a production-grade, streaming data pipeline even though the result is “just” descriptive and does not include a complicated machine learning model. |
These use cases are profoundly different from those of low or medium complexity in that they require a deeper embedding into the business process and more automation. For example, one international telecommunications company wanted to automate their e-mail marketing using machine learning to determine the right audience for their campaigns. Their data scientists created highly accurate models to identify contacts most likely to be interested in a particular e-mail’s message. In order to create business value from these models, they needed to be integrated with existing marketing automation tools and processes. Besides porting the models from the development environment to the production Hadoop cluster (compare deep dive below for more information on the potential challenges involved in this step), this involved creating interfaces to the marketing automation software and change management to align how marketing tools uses the software with the new business process. |
.
Deep Dive: Technical Deployment of Machine Learning Models
.
Machine learning models are typically developed in a scripting language (most commonly Python or R) using a framework that allows for fast iteration (such as scikit-learn, H2O, PyTorch or Keras).
When deploying these into automated processes, two main properties need to be ensured:
- The models must reliably make correct predictions on different infrastructure and in a separate software environment from where they were trained (e.g. the production server or cluster, on premise or cloud)
- These predictions must be produced fast and reliably enough to meet the application’s requirements
Depending on the nature of the production system, a combination of the following methods can be employed to guarantee these properties:
- Translate the trained models into a standardized format (such as ONNX or POJO) to make them executable using standard tools (e.g. the Java for POJO) or importing them in a production-focused machine learning framework (e.g. Caffe2 for PyTorch before v1.0)
- Use Docker containers to encapsulate the dependencies of the developed application
- Build a REST interface to allow for standardized communication with other systems
While the tools available for supporting this transition are becoming ever more capable, it is still challenging and requires a close collaboration between data scientists, data engineers and the IT operations team. Especially in the context of distributed systems where many technical complexities arise from the mere fact that high level tools like Python need to be integrated with the Java Virtual Machine and C-level dependencies on a potentially heterogenous cluster of machines. The industry is currently in a state of experimentation into how to get around such issues. Encapsulating application dependencies in containers and deploying these using frameworks such as Kubernetes and Kubeflow is probably among the most promising approaches.
The factors that influence the probability of a successful deployment vary according to the specific deployment category. For example, the first category is typically straightforward in technical deployment as they often have more of a one-off character and do not have to be embedded deeply into existing business process like use cases in the other two categorie. However, the factors we will outline below will most likely impact your data product’s success independent of the deployment category of a data science project.
.
3. Why is creating value from data science projects so difficult?
But what exactly is it that makes creating value from data science projects so difficult? The reasons are manifold and range from the characteristics of the underlying data through the humans involved and how they collaborate to technological challenges:
Data: The good, the bad, and the ugly
Most data scientists will nod in agreement when we say that more often than not the raw material they are working with is rather “dirty”. In the industry, a common saying is that data scientists spend 60-80% percent of their time doing some kind of plumbing work – cleaning, aggregating, pre-processing data for later analyses . In the worst case, these data quality issues are manifested in manually filled fields containing tons of errors and missing values, which makes working with the data cumbersome.
Even when quality data is available, it is not always easily accessible as data ownership is unclear and lengthy, heavily formalized approval processes stand in the way of the data scientist. This is because in most traditional companies, data science was not a consideration when the data generating processes were designed and set up. Data was collected for other reasons than creating business value by analyzing it. Here lies a key difference to “data-native” technology companies like Google or Amazon: Their operations are centered on creating value from data and have been from the beginning of their existence.
Another common hurdle that has its roots in a lack of experience with data-enabled products and services is the omnipresent uncertainty about data privacy and security.
The catch with these challenges is that most of them can initially be ignored or temporarily overcome to get a Proof of Concept (PoC) going. Difficulties in data access are sidestepped by working on extracts – which is totally fine if a plan for automatic access exists, but causes serious problems in deployment if not. A productive system needs regular and well-defined access to all relevant data, a situation that is different from a PoC not just in degree, but in kind. Unfortunately, the same mechanism holds true for issues related to privacy and security or data quality. Even the dirtiest table of data can be brought into shape with a customized script written by savvy data scientists, but more often than not these workarounds come at a significant cost (cp. chapter 4.3). Similarly, a data project that needs to be scaled across several countries to deliver adequate return on investment may fail to do so due to data privacy concerns that were generously overlooked at its inception.
The humans in the loop
As with most things in business, data science projects are not primarily about data, algorithms or technologies – they’re about humans. We’ve seen promising PoCs stall because they didn’t get the leadership attention and support they deserved. Part of the issue here is that many organizations do not have a clear strategic direction for their data science activities which makes it hard for data science teams to argue how their work contributes to larger objectives. What’s more, the understanding of data science topics across the broader organization is still in its infancy at most traditional companies – maybe not surprisingly as it is difficult to separate the signal from the noise amid the current excitement around artificial intelligence and machine learning.
In addition to a basic knowledge and appreciation for data science, experts with complementary skills who work in cross-functional teams are needed to successfully deploy data science projects. This includes resources with profound software engineering knowledge who work with data scientists to make their models production-ready. However, from our experience this optimal constellation is rare. While the scarcity of data scientist and the mismatch between supply and demand has been extensively discussed, we are observing an ongoing diversification of the roles needed in successful data science projects. Especially data and machine learning engineers, i.e. individuals who combine data science knowledge with profound software engineering skills, are incredibly valuable for data science deployment and still come up short in many discussions.
Organizational hurdles
The digital transformation has profound impacts on the way traditional organizations do business. In particular, the role of the IT department is changing. Many companies are just figuring out what these changes mean for their organizational structure, processes and collaboration models. Driven by the popular narrative around the need for a “two-speed IT” (McKinsey – Two-Speed IT), innovation and data science labs mushroomed across industries over the last five years (Capital – Digital Innovation Units Study). The underlying rationale was to enable the fast iteration and experimentation needed to bring about innovation. However, many companies found that this structure causes a detachment between “traditional IT” and the innovation lab, thereby creating enormous frictions in deployment. These frictions manifest across several dimensions: (1) The methodologies used in traditional software development (think Waterfall) differ substantially from those needed to bring data innovation to life (agile, iterative, experiment-driven). (2) Traditional IT is often not prepared (both skill- and technology-wise) to assume responsibility for monitoring and maintaining deployed analytical models at scale. (3) Continuous iteration and integration between data science development and operations becomes cumbersome. These factors cause deployment to be perceived as requiring to cross an organizational chasm by many data scientists we speak with.
Technological boundaries
To be clear: Technology is never the root cause of an issue as in most any case you could just use another tool – and if not it’s usually not the technologies fault. Yet, the rapid technological development around “big data” can be overwhelming. A plethora of tools ranging from data infrastructure through open-source machine learning software to purpose-specific enterprise applications has surfaced to tackle any data task (Big Data Technology Landscape 2018). The speed of development leads to several challenges: (1) Traditionally, many IT organizations used a blueprint of supported technologies to structure their operations. With innovations from the open-source world being adapted quickly among data scientists (think Apache Spark for data processing), IT must react and change faster than ever before. (2) The most suitable technology changes with the data project’s maturity. Data scientists love high-level, interpreted languages like Python or R and prefer to work with data in an interactive way (Kaggle – The State of Data Science and Machine Learning). These preferences are well suited for experimental work in the PoC phase of a data project. However, they only rarely work well in a productive setting. When data volumes are large and performance is key, lower level languages or production frameworks are needed. These tools emphasize speed of execution and stability over flexibility in development. Please refer to the deep dive box on the technical deployment of machine learning models above for more information on this challenge.
Problems everywhere – do you want to have tips and best practises on how to deploy data products? Just read the second half of this article here.
 Data scientist, instructor and Amazon bestselling author.
Data scientist, instructor and Amazon bestselling author. {kind=link}