Reading time: ~10min
Level of technicality: low, no previous knowldge required
Summary:
- Data can be distinguished along many dimensions. The most important one is the degree of organization
- When differentiating by means of the degree of organization between data, we classify it into three different types: structured, semi structured and unstructured data
- The distinction is not always clear cut and should be understood as a continuous scale, rather than three distinct categories
- The type of data has implications on how the data should be stored, how machine-readable it is, and how easy it is to analyze it
In my previous blog post I talk about what data is. In this article, we will see what different types of data there are. The distinction between different types of data is important because it impacts how data can be stored, how it should be organized and how easy it is to process and analyze it. This applies to all data, regardless of what sector we are looking at. In this article we will look at
- Various criteria by means of which data can be distinguished
- The distinction along the degree of organization into structured, semi structured and unstructured data
- Why this distinction is so important
- Tips for how should set up your data generating process and what type of data you should collect
Data Classification Types
Recall from this blog post that put very simply, data is nothing else than information stored in digital format. It should be clear then, that data can take many forms. Consequently, there are many different criteria by means of which we can classify and categorize different data forms (i.e. there are various taxonomies).
You might recall one data classification type from your college times. In an academic context we often distinguish between quantitative (consisting of numbers) and qualitative (consisting of non-numbers) data. If a sociologist conducts an interview, this is qualitative data. If an economist is comparing the GDP and other economic indicators of various countries, they are dealing with qualitative data.
Or, if you are working in a company a distinction of data is often made depending on what entity or business process data refers to. For instance, in a business setting we will often speak of customer, employee and sales data.
Another data classification type that is often used in a business setting is also the distinction between master and transactional data. Master data is usually static data that rarely changes and reflects business objects that are shared across a company such as customer data (the name, address and contact details of customers change relatively rarely). Transactional data is usually non-static data with a temporal dimensions which describes and event and transactions such as product orders or website logs.
There are many more data classification types and all of them can be helpful depending on the context we are in.
However, arguably the most important data classification type is along the the degree of organisation. We can distinguish between structured, semi structured and unstructured data.
What is structured, semi structured and unstructured data?
Structured data is data with a high degree of organization, typically stored in a spreadsheet-like manner. Semi-structured data is data with some degree of organization. And unstructured data is data with no predefined organizational form and no specific format, so essentially everything which is not structured or semi-structured data.
The following table gives a brief overview of structured, semi structured and unstructured data.
| Structured data | Semi-structured data | Unstructured data | |
| What is it? | Data with a high degree of organization, typically stored in a spreadsheet-like manner | Data with some degree of organization | Data with no predefined organizational form and no specific format |
| To put it simply | Think of a spreadsheet (e.g. Excel) or data in a tabular format | Think of a TXT file with text that has some structure (headers, paragraphs, etc.) | Essentially anything that is not structured or semi-structured data (which is a lot) |
| Example formats |
|
|
|
| Characte- ristics |
|
|
|
As you can see, the distinction breaks down to how organized your data is.
Why is the distinction between structured, semi structured and unstructured data important?
As you can see, the distinction of structured, semi structured and unstructured data breaks down to how organized your data is. But why is the degree of organization so important? There are many reasons, but the two reasons that stand out are:
- Machine-readability
- Implications for data storage
If data follows a rigorous structured like in a spreadsheet from which there is no deviation, then this make the data highly machine-readable. As a result, we can analyze even large datasets very easily by harnessing computer power.
In contrast, if data does not follow a rigorous structure, it might still be easy for us consume as humans but is usually not very machine-readable. So to harness computer power to analyze it will be much more difficult.
Consider this example to grasp this idea: Let’s say I am organizing a workshop with 10 participants and I want to create list of basic workshop participant data. On the one hand, I could have every participants enter their name and age into an Excel sheet upon arrival. Or I could have everyone write down their name and age on a name tag (i.e. physical piece of paper) and then take a picture of all name tags.
In the first case I can directly use my computer and perform operation on the data. For example, I could use a simple tool like Excel to display all participants older than 40 years, or I could filter for a participant name to look up their age. I cannot do that with a computer if I had an image of all participant’s name tags. I could of course do it manually, but there is no software tool where I can tell my computer to give me the age of participant X (we are getting there with image classification and object detection, but I hope you get the point).
As we will see, the distinction is also important because it has implications on how data can be stored.
What is structured data?
Structured data is data with a high degree of organization, usually stored in some sort of spreadsheet. Simply think about a (well organized) Excel sheet, which is a prime example of structured data.
Even though we are currently making major progress in processing and thus also in gaining valuable insights from semi-structured and unstructured data, structured data is often considered more valuable. The reason is that it can directly be leveraged with computer power without major the need of major pre-processing steps. We can easily use structured data for data visualisation, data analytics and machine learning.
Unfortunately, there is no data on what the distribution of data between structured, semi-structured and unstructured data looks like. However, it is often said that structured data only makes up 20% of all data[1]. This seems reasonable if you consider that a major data source of today are our smartphones, with which we listen to music, take pictures and create videos (all of which is unstructured data).
Structured data examples
Figure 1 shows customer data of Your Model Car, using a spreadsheet as an example of structured data. The tabular form and inherent structure make this type of data analysis-ready, e.g. we could use a computer to filter the table for customers living in the USA (the data is machine-readable).
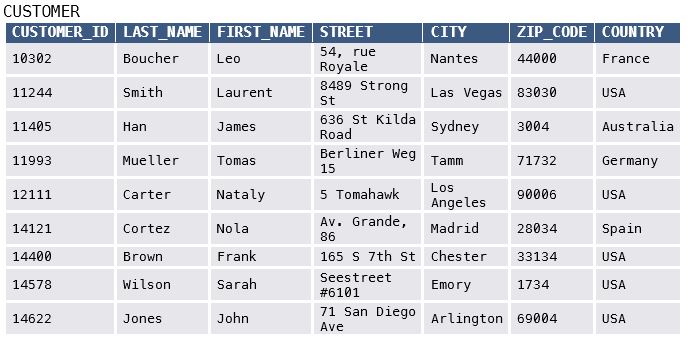
Figure 1: Example of structured data
Typically, structured data is stored in spreadsheets (e.g. Excel files) or in relational databases. These formats also happen to be pretty human-readable as figure 1 shows. However, this is not always necessarily the case. Another common storage format of structured data are comma separated value files (CSV). Figure 2 shows structured data in csv format. While it might look messy at first, if you look closely it follows a rigorous structure that can easily be converted into a spreadsheet-like view. Each row has a value for a product code, order number, etc. These values are separated by a semi-colon “;” so they can easily be related to the right column header. For example, every first value in a row indicates a product code.

Figure 2: Structured data in csv format
Structured data is typically stored in relational database systems. Relational databases are from the “digital stone ages” and have been around for a few decades already which is remarkable given how fast paced and innovative the IT world is.
What is semi-structured data?
Semi-structured is data which has some degree of organization in it. It is not as rigorously structured as structured data, but also not as messy as unstructured data. This degree of organization is typically achieved with some sort of tags or other elements with defined properties which introduce a hierarchy and system into a file. However, the order and amount of such structuring tags and elements may vary. Therefore, the structure imposed on a dataset it not as rigorous as in structured datasets where all data has to conform to the structure of the data table (spreadsheet).
Semi structured data examples
If wanted to see an example of semi-structured data, you have been looking at one the entire time! You are currently reading a hypertext markup language (HTML) file. HTML is one example of semi-structured data, in which a text and other data is organized with tags. For example, all headers you see in here have a header tag
or
. These tags somewhat organise this file and help your browser rendering it and making sense of it. However, on a different webpage the number and type of tags used might be completely different.

Figure 3: Example of semi-structured data
Figure 3: Example of semi-structured data
Another widely used type of semi-structured are JSON files. This figure below a JSON file containing employee data. As you can see, JSON files have an inherent tree-like structure that gives some degree of organization, but it is less strong than in a table. Therefore, analysing the data by using simple filter options is partly possible, but more cumbersome than with structured data (think of how easy that is with Excel’s filter functionality).
What is unstructured data?
Unstructured data is data with no pre-defined organizational form or specific format. Or in other words, unstructured data is any data which is not structured or semi-structured. This can literally be data of any file format which is not nicely put into a spreadsheet or some semi-structured data format.
The vast majority of all data created today is unstructured. Just think of all the text, chat, video and audio content that is generated every day around the world! Unstructured data is typically easy to consume for us humans (e.g. images, videos and PDF-documents). But due to the lack of organization in the data, it is very cumbersome – or even impossible – for a computer to make sense of it. That is why we say that it is less machine-readable. However, with the advent of AI and more sophisticated machine learning methods, we are currently making a lot of progress in processing and essentially teaching a machine how to make sense of unstructured data. For example, the fields of natural language processing (NLP) and computer vision are witnessing significant breakthroughs at the moment.
Unstructured data examples
There is a plethora of examples of unstructured data. Just think of any image (e.g. jpeg), video (e.g. mp4), song (e.g. mp3), documents (e.g. PDFs or docx) or any other file type. The image below shows just one concrete example of unstructured data: a product image and description text. Even though this type of data might be easy to consume for us humans, it has no degree of organization and is therefore difficult for machines to analyse and interpret.

Figure 4: Example of unstructured data
Storing unstructured data
For decades, before the dawn of unstructured data, most of the was stored in so called relational databases. The idea of such relational database is to store data in interrelated tables. Relational database are still the most prevalent type of database today, which is quite remarkable given their age. But there is a reason for that: they are extremely powerful and versatile.
However, they are also not perfect and ideal to use in any situation. One of their shortcomings is that they cannot store unstructured data (how would you store images in interrelated spreadsheets?). Because the majority of today that is crated today is not structured, in the past years we have seen new storage technologies and methods mushrooming in the industry that are able to efficiently store unstructured data. For example, AWS’ S3 service is a so called object storage service, in which you can basically chuck in any type of data.
Structured vs unstructured data
To clarify the difference between structured and unstructured data and its implications consider this example: Image you have employee data of your company, which has 100 employees, in two formats. First, as an Excel spreadsheet with several columns such as “First name” and “Age” (structured data). Second, as an image of that Excel sheet (unstructured data).
Now let’s say you are trying to find a guy called “Gary” in your data. In the Excel sheet we could simply apply the filter functionality and filter for the name “Gary”. Now, in the image, i.e. the unstructured data which is not machine-readable, you would be able to point to and find the entry of Gary by looking at the image. To us, this comes effortlessly. However, for a machine to make sense of an image is extremely difficult. Because unlike you, what the computer sees are millions of numeric RGB codes and not an image at all. Because we are making advancements in the field of computer vision, this is not impossible for a computer anymore. However, you should the point that structured data is just so much easier to consume and process for a computer.
Conclusion
In this article you learned
- How data can be classified into structured, semi-structured and unstructured data
- What examples of the three data types are
- Why this distinction is important and what its implications are
[1] https://www.forbes.com/sites/bernardmarr/2019/10/18/whats-the-difference-between-structured-semi-structured-and-unstructured-data/#46e322082b4d
 Data scientist, instructor and Amazon bestselling author.
Data scientist, instructor and Amazon bestselling author.