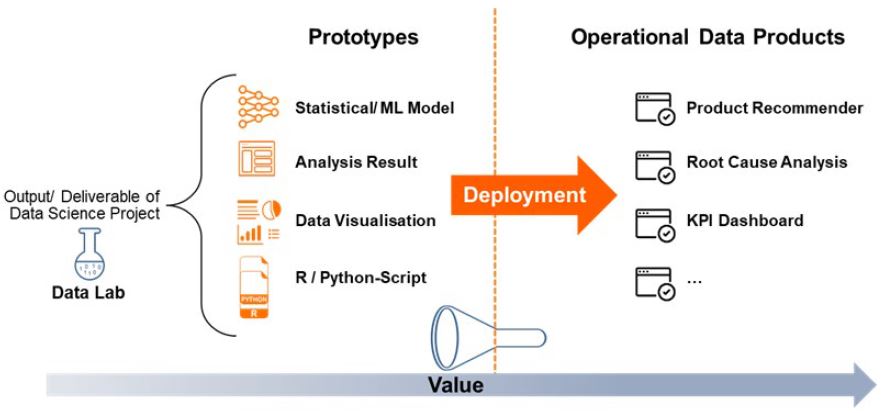
In the previous post we saw why a lot of data projects get stuck at what I call the “data science bottleneck”, i.e. the step of deploying a data product prototype in an operational environment. If you haven’t read that article make sure to have a look at it here.
In this article we will look at some tips and best practises on how to overcome the challenges when deploying a data product. It is the product of both both personal experience in projects and the collective experience of 500+ projects that the team at Alexander Thamm GmbH has implemented.
Executive Summary:
The 7 best practises to overcome the so called “data science bottleneck” are:
- Focus and invest in data engineers, to cope with data science projects turning into software development projects
- Work in interdisciplinary teams consisting of business experts – data scientists / engineers – IT to align requirements, development and operability of your data product.
- Be aware of and carefully consider taking on technical debt, i.e. prioritizing short-term benefits over high costs in the long run.
- Consult data scientists when updating or designing data generating processes to enable future use cases.
- Invest in data governance to alleviate data quality and availability issues. These factors jeopardize the success of data science projects all along their life cycle, but become especially severe during the deployment phase.
- Use the cloud and the rapid innovation in the space to your advantage.
- Build a foundation for advanced use cases by investing in data acquisition and make sure your project contributes to your organization’s larger data strategy.
.
The last step in a data science project is arguably also be the hardest, i.e. taking the prototype that hopefully fulfilled its purpose as proof of concept (PoC) and finally deploy it. Recall from the previous post that deploying a data product means to make the output of a data science project (e.g. a machine learning algorithm or visualisation dashboard) available to its users by integrating it into the respective business process. This is much easier said than done in practise. Here are some tips that hopefully help you overcoming the hurdles of data product deployment:
.
1. Have data engineers on board
In the past months and years, the data science job has been coined as “the sexiest and most wanted job profile of the 21st century”. While they are indispensable for the success of a data science project, the role of data and machine learning engineers is at least equally important. Data Scientists are typically involved in the development and prototyping phase to explore the data, experiment with it, engineer features from it and finally develop machine learning and statistical models. As we have seen in the previous article, the real bottleneck of many data science projects, however, is the deployment – the job of data and machine learning engineers.
When a prototype (e.g. a machine learning model) is deployed, the “data science project” turns into a “software development” project. These are two very different things. To see why, consider the development of a new car. In the R&D phase many adjustments to the car can be customized manually, for instance shaping the body in a specific way to ensure optimal aerodynamic properties. The goal is to test and create optimal features of a given prototype. However, if such a prototype is to go into mass production the goal changes to producing as many cars as cheap as possible with a high quality. Some features of the prototype might have to be compromised for ensuring cheap and high quality production. This is a whole new challenge and very different from the R&D phase. You cannot just give your car to the head of production and expect it to be produced in thousands immediately. It is very much the same for data science projects.
During the development a lot of things (e.g. correcting errors in the data) can be done manually by the data scientist. But if a final data product is to be put into production, this is often a new project in and of itself and a whole new challenge.
The data product needs to be tested and designed to be fault-tolerant and meet the performance requirements. This takes time and engineers with the right skills, ideally with a background in both software development and data science / machine learning knowledge. So for every data science project, you definitely need an engineer on board. To take it one step further, we would even recommend that when composing your data science team, you should aim to have MORE engineers data scientists.
.
2. Operate data projects in a cooperative triangle of business department, data science unit and IT ops
In silo-organized companies, data science teams often operate with little or no cooperation with other departments, notably the IT and business departments. In the implementation of data science projects the cooperation in a triangle of data science / engineering – business department – IT in one team is crucial to foster a successful deployment of the resulting product. The business department, i.e. the users of the data product, should regularly communicate their requirements while the data science team together with IT should assess the technical feasibility and try to find solutions to resolve any mismatches between requirement and feasibility. This prevents implementing projects that meet the requirements but are not deployable from a technical point of view or vice versa.
For example, in a predictive maintenance use case for production machines, the business department needs to define how they want to use the data product. How much time in advance should failures be forecasted? How high does the accuracy need to be in order to have a profitable business case? These requirements will have to be translated by the data science team and assessed with the IT department: What is the granularity of the sensor data – milliseconds, seconds, minutes? Is it being pre-aggregated? Is this frequency sufficiently high to make predictions this long in advance? What computational power and tool will be necessary to implement the use case (e.g. is there a distributed system in place that can cope with the computational load)? What is the target environment for deployment and does it feature the necessary tools? And so forth.
The cooperation of these stakeholders ensures that data science use cases are not set up with a mismatch between requirement and feasibility hindering their deployment.
.
3. Be aware of the costs of technical and organizational debt
The concept of technical debt is well known in software development. It refers to situations where one opts for a solution that is easy to implement in the short run, but is not optimal and comes at costs in the long run (i.e. “quick-and-dirty solutions”). These detrimental effects grow in the long run as the debt accrues, e.g. code may be slower to run or harder to maintain and improve.
Such technical debt also exists for data science projects (compare here). Situations like “let´s hard code this data transformation for now, because we need to show some results tomorrow” will certainly sound familiar to data scientists. They will also know that as the projects continues, not refactoring, i.e. cleaning up, such technical debt can come at high costs in the long run.
Like in economic theory “debt” is not necessarily bad, but the costs and benefits need to be carefully considered in data science projects. Besides technical, consider organizational debt as well:
3.1 What is technical debt?
As explained above, this is mostly relevant for developers and data scientists: When writing code, it is always tempting to go for quick-and-dirty solutions, especially given time pressure. But such solutions backfire when it comes to deploying data science projects as they may hinder readability of the code, maintainability and performance. Examples of technical debt in a data context include:
- Using tools that are comfortable to use in development but do not have a good performance or are difficult for deployment (e.g. R for performance-sensitive applications)
- Hard-coding and manually calculating instead of writing code that is designed for stability and is tested against corner cases (i.e. development testing)
- Not spending enough time on code documentation
These issues are well-known in the software engineering discipline. However, as many data scientists come from backgrounds other than computer science, some of them had to be learned the hard way once again.
3.2 What is organizational debt?
The underlying mechanism of technical debt applies on an organizational level as we and is especially relevant for managers and decision makers. Examples include:
- The incompatible technical tool stack between innovation lab and core IT described in chapter 3 is a consequence of decision makers (unwittingly) taking on the organizational debt of building a lab as “speed boat” detached from the cruise ship that is enterprise IT
- On a project level, going forward with PoCs where tool incompatibilities, lack of regular data access, data quality deficiencies or one of the other possible causes for failure outlined in chapter 4 are generously overlooked should be viewed as organizational debt
Incurring such debt is not necessarily bad – it can be useful and even needed, for example if a PoC needs to be delivered very quickly. But if such debt is incurred, one needs to be aware of the accruing costs, be sure that it is worth the benefits and should have a plan to repay it.
.
4. Consult data scientists when designing or updating data generating processes
Most companies sit on tons of data already and have been doing so for a long time. Cool. However, the data traditionally collected was generally not meant to be used to create value from it. Instead, it was saved for reporting or regulatory purposes for example. Therefore, for some data science use cases, many organizations just don’t have the required data (quality). Unfortunately, this can sometimes be overcome in a PoC context, most likely using manual methods not suited for being applied in production. Still, for a strategic use case (cp. chapter 4.7), companies may want to work on their data basis to make it happen. If so, or if a data generating process is reworked for some other purpose, please rember to consult data scientists and engineers in designing these processes! This way, you can make sure that valuable future use cases are possible thereby making better use in the investment of reworking the process.
For example, if new sensors are included in a car, a machine, an IoT device, an elevator, … in order to collect data for logging purposes, data-savvy colleagues might have an idea or two on how exactly the data should look like (frequency, which measurements, etc.) to facilitate a predictive maintenance use case. These requirements by data scientists will also have implications for the business case. If data that needs to be collected for one purpose unrelated to data science, but can be used for three data science use cases it may become viable to increase the measurement frequency for example.
.
5. Invest in data governance as you would in any other valuable capability
Everyone, who has worked with data before, will know that typically the biggest show stopper is data quality (e.g. a lot of N/A fields, implausible values etc.) and availability (e.g. getting hold of data from other departments, few observations and variables, etc.). This is partly because when the data generating processes in companies were put in place, they were not designed to collect data to implement data science use cases. More importantly, however, it is because of a lack of (or poor) data governance, i.e. the pro-active management of data to ensure its availability, usability, quality and security in a company. Being one of the “necessary evils” (and a key enabler) rather than a shiny buzzword data governancy has received much less attention and money than exploring “AI algorithms” for example – which is unfortunate. While the immediate benefits can’t be ready observed, the alleviation of data quality and availability issues it brings when done well is formidable:
While in a prototyping phase of a use case, some of the issues that a lack of data governance brings along can still be alleviated, often the problems become so exigent during the deployment phase that they jeopardize use cases going into production. For example, during the development phase quality issues in the data can often be corrected manually (e.g. imputation of N/A values), but automating such solutions is typically a lot harder because all contingencies will need to be taken into account. Or a data product might work perfectly in one market, but can not be rolled out to other markets because of a lack of necessary data that is not available there.
So poor data governance causes problems all along the life cycle of a data science use case.
A lot of pilots will fail during the development phase due to poor data quality already. But the consequences of poor data governance hit even harder in the deployment phase.
.
6. Use cloud services
Adoption of the public cloud is becoming mainstream with a prominent example being Netflix, which has finalized its move to AWS in 2016, leading the way. We believe that this is a great development for the productive use of data science and machine learning. Here’s why:
Infrastructure as a Service (IaaS) solutions provide the flexibility data science projects inherently need. Most data endeavors ask for an exploratory approach that benefits from quick iteration and frequent experimentation. The cloud offers scalable, cost-effective storage and computing that seamlessly adapts to the fluctuating demands of a typical data science life cycle. What’s more, cloud providers have recently begun to offer increasingly specialized infrastructure for cutting-edge machine learning methods such as Deep Learning. In some cases, this hardware is only available through the cloud and can greatly enhance the speed of development. The configurability of most cloud services greatly facilitates deployment as the development environment can easily be set up as a mirror of production, thereby making the transition less error-prone.
But it is not just infrastructure that is offered through the cloud: Increasingly, value-added services such as pre-configured machine learning solutions like Google’s AutoML or Amazon’s Sagemaker are being offered in the arm’s race for dominance among the large cloud providers (most notably Amazon Web Services, Microsoft Azure, Google Cloud and IBM Cloud Computing).
Turning back to its core, cloud computing allows organizations to abstract away from basic operations work. In a time when data scientists are still scarce and data and machine learning engineers loom ahead to form the next resource bottleneck, this is more important than ever. These high-skill, expensive resources must be relieved from operations work by leveraging “infrastructure as code”. What is more, they are usually ill-prepared to do the highly specialized operations work required to successfully administrate a large-scale Hadoop cluster for instance anyway. In most organizations, which do not have years of experience working with Big Data technologies, the same will be true for the IT department. And understandably so: The foundational big data analytics tools such as Google File System, Map Reduce and Big Table were developed at Google in the early 2000s. Since then, the technology companies offering the successors of these tools as cloud services today have certainly learned a few hard lessons from being primary users themselves. Thus, traditional companies must decide whether the capabilities involved in building and maintaining state-of-the-art infrastructure for data science and machine learning provide any competitive advantage to them. Having said that, one thing is a given for us: Not having access to this kind of infrastructure is a disadvantage that will make it next to impossible to compete in all major industries in the upcoming years.
.
7. Reality check your project and embed it in an overarching data strategy
Setting aside all technical intricacies and the details of the deployment process for a moment: The foundational asset of a data-enabled organization is a clear vision and strategy for creating value from data. One core manifestation of this is how leaders go about acquiring the right data to achieve their strategic goals.
Google’s effort to collect images of every street in the world through their Street View program provides a vivid example. Street View came into existence as a spin-off of the company’s early steps towards developing a self-driving car (read the full story in this CNBC piece on GoogleX founder Sebastian Thrun). The company realized early on that this investment in data collection would provide benefits far beyond better orientation for Maps users. In an initiative led by Google’s founders Larry Page and Sergey Brin, Street View became the first project within the GoogleX department, which hosts the organization’s “moonshot projects”. In the meantime, Street View imagery has been used not only to arguably make faster progress on self-driving cars than any competitor, but to substantially improve Maps as well.
The same underlying mechanism holds across all industries: To benefit from advanced data science and AI use case, strategic investments in data acquisition are necessary. For example, Vorwerk made it a priority to build a real-time data pipeline that collects and aggregates data produced by more than 1.5 million connected Thermomix devices worldwide. In addition, they invested in state-of-the-art infrastructure, both on-premise and in the cloud. Now they can capitalize on these investments through a variety of advanced use cases.
Unfortunately, the reverse is also true: Many data science projects fail because the available data makes them impossible. Combined with the high expectations frequent reports on the potential of AI have raised, this is is a shortcut to disappointment. We certainly believe in the potential of creating value from data. At the same time, we have seen time and time again that digitization must precede data science. There is no point in trying to implement advanced use cases when the data basis is just not there yet. Instead, assess the data readiness of each function and develop an overarching data strategy. Focus on low-hanging fruits first and feed the leanings from use case implementation back to steer the strategic focus. Create a feedback loop by simultaneously laying the groundwork for more advanced use cases and executing the ones your organization is ready for. This way, you will be able to keep spirits high and gradually work towards those futuristic AI use cases everyone’s talking about.
.
Conclusion
.
In this and the related previous article, we looked at how currently a lot of data science projects fail at the deployment stage. We defined deployment as the stage where a data science PoC or pilot’s outcome is turned into an operative data product and integrated into the business process. We looked at different forms of technical deployment for data science use cases and identified five key challenges: (1) Data accessiblity and / or quality is not good enough to facilitate sustainable value creation. (2) Data privacy and security concerns prohibit scaling. (3) There are not enough data and machine learning engineers available to help deploy what data scientists produce. (4) In many companies, there is a large organizational gap between business, data science and the IT department. (5) The technology landscape is quickly evolving and enterprise IT is not prepared to operate the technologies used in innovations and data labs.
.
We have further shared best practices to overcome these challenges and bring data science projects closer to creating real value: (1) Have data engineers on board. (2) Work in interdisciplinary teams. (3) Carefully outweigh costs and benefits of technical and organizational debt. (4) Involve data scientists in the design of data generating processes. (5) Implement good data governance. (6) Use the cloud to your advantage. (7) Make sure your project contributes to a larger data strategy and lay the groundwork for advanced use cases early.
 Data scientist, instructor and Amazon bestselling author.
Data scientist, instructor and Amazon bestselling author.